Boa for Big-Code Mining and Large-Scale Static Analysis
Tutorial for generating new Boa dataset by mining GitHub open source repositories

This tutorial will describe how to create your own Boa dataset for specific projects in Github and run Boa queries on that dataset locally. We will use command line and Eclipse IDE for that purpose.
Prerequisite
You need to have following already installed in your system:
- JDK
- Apache Ant
- Git
- Eclipse IDE
Development Setup Steps
- Clone the Boa project using the command line:
git clone https://github.com/boalang/compiler.git - Go to the cloned repository:
cd compiler - Clean the project:
ant clean - Create a directory for libraries:
mkdir -p build/classes - Compile the project:
ant compile - Create a class folder:
mkdir compile - In Eclipse go to: File > Open Projects from File System > Import Source – Directory > Browse the cloned repository (compiler) > Hit Finish
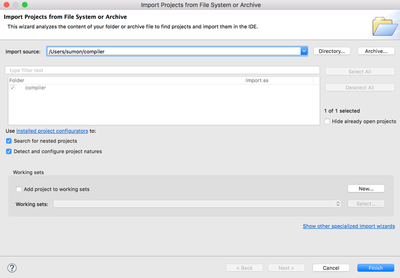
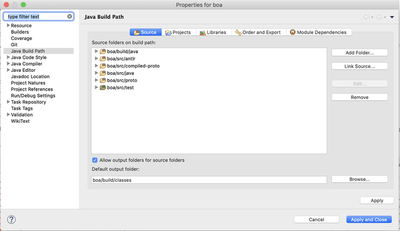
- Right click on the project compiler > Build Path > Configure Build Path
- In Source tab, click Add Folder to add the required source folders and remove unnecessary folder(s). After adding all the folders, the window should look like the following:
- Select Libraries tab in the same window and click on Add Class Folder and add the compiler/compile folder that has been created in step 6.
- Click Add JARs… in the same Libraries tab > select lib > select all the files inside lib, including files under datagen and evaluator folder > hit Apply and Close.
- From the compiler project in Eclipse, right click on build.xml > Run as > 1 Ant build. This should build the project successfully. The development setup is completed. Now, we will move on to data generation steps.
Boa Data Generation Steps
- Go to github.com and search the project for which you want to create the dataset. For example, if you want to create dataset for Apache Mavan project, go to https://github.com/apache/maven .
- Invoke a GitHub http-based RESTful API to get the metadata of the project by constructing a URL https://api.github.com/repos/repo_full_name, for example https://api.github.com/repos/apache/maven.
- Copy the whole JSON metadata, create a blank text file, type a pair of brackets ‘[]’, paste the metadata inside the brackets.
- Search for “languages_url” field in the JSON data, go to the URL, copy everything, create another field in the JSON file (“language_list”: ), paste copied text and save the file as filename.json (e.g., maven.json). The last few lines of the JSON file should look like:
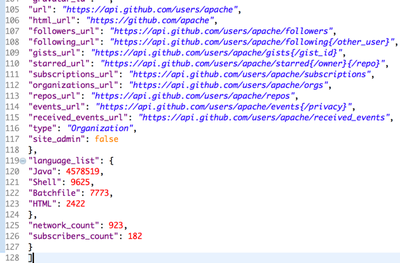
- In this way, for each project, that will be included in the dataset, create a JSON file. So, if you want to create a dataset for 5 projects, you will create 5 separate JSON files. Save all the JSON files in a folder. Alternatively, you can create a single JSON file for all of the projects by separating them by comma in an array ‘[]’. The format looks like [{}, {}]. Each curly brace is for one project.
- In Eclipse, go to the project compiler > src/java > boa.datagen, right click on BoaGenerator.java > Run As > Run Configurations.
- Double click on Java Application to create a new configuration. Browse project and select compiler, Search Main Class and select boa.datagen.BoaGenerator.
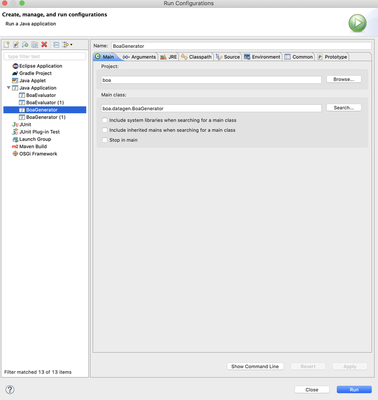
- Select Arguments tab and add program arguments. The program arguments format should look like:
-inputJson <directory containing project JSON files>
-output <output directory of the dataset (folder will be automatically created)>
-inputRepo <temporary directory used to clone the projects (this folder will be automatically created)>
The other arguments are optional. For example, to print debug messages in console use -debug.
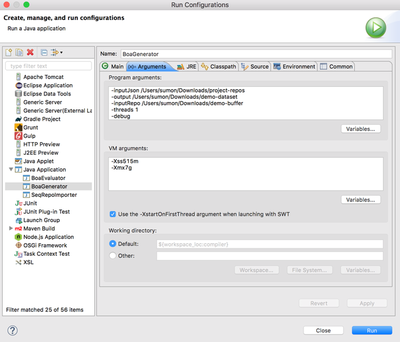
- Hit Run.
- This should start cloning the projects form Github and generating dataset. Depending on the number of projects and size of the projects, this will take some time to finish. When the red Terminate option in the console goes off, the data generation process is finished.
Run Boa Query on New Dataset
- Create a dataset folder copying three files (projects.seq, ast/data, ast/index) from the generated output folder from step 8 of data generation process.
- In Eclipse, go to the project compiler > src/java > boa.evaluator, right click on BoaEvaluator.java > Run As > Run Configurations…
- Create a new configuration by clicking the New Configuration in the upper left corner of the window.
- Give a Name to the configuration, Browse project and select compiler, Search Main Class and select boa.evaluator.BoaEvaluator.
- Select Arguments tab and add program arguments. The program arguments format should look like:
-input <file path to the boa source code file>
-data <dataset directory containing three files(projects.seq, data, index)>
-output <output directory>
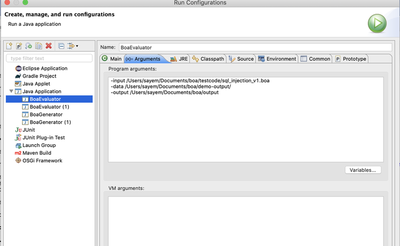
- The output of the query will be printed in the console.
The screencast to go over the above steps and setup Boa development environment is shown in the following video.