Operational Safety of Autonomous Coding Agents
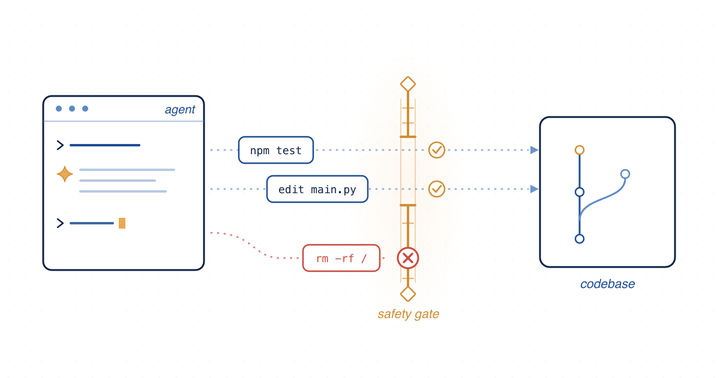
Autonomous coding agents built on large language models are being wired directly into development workflows — editing files, running commands, configuring environments, and fixing bugs with growing autonomy. Their promise is enormous, but so is the blast radius when they go wrong. This project studies the operational safety of AI coding agents: what it means for an agent to behave safely when it is given real access to a real codebase, and how to engineer that safety before, not after, something breaks.
Most safety evaluations of these tools focus on explicitly malicious prompts. We argue that this misses the larger and more common danger: agents that fail during ordinary, well-intentioned work. A broad understanding of operational safety has to account for failures that emerge from the agent’s own initiative — destructive operations, constraint violations, authorization bypasses, and silent errors that surface only after damage is done. Our research direction is to characterize these risks empirically, build taxonomies and benchmarks grounded in real usage, and translate the findings into concrete safeguards: environmental constraint enforcement, failure transparency, and safe-halt capabilities that let an agent stop rather than push forward into harm. This connects naturally to our broader interest in the reliability and reasoning of LLM-based systems.
A concrete instance of this work is What Breaks When LLMs Code? Characterizing Operational Safety Failures of Agentic Code Assistants, to appear at the IEEE/ACM International Conference on Automated Software Engineering (ASE 2026). We triangulated two evidence sources — screening 68,816 papers across 22 premier venues and mining 16,586 GitHub issues from LLM-powered coding tools — to confirm 547 genuine safety failures, and developed a taxonomy of 33 operational risk types across seven dimensions. The findings are striking: over 65% of incidents arise during routine bug fixing and setup or configuration tasks, and 326 of the 547 incidents were rated high or critical severity. Everyday development, not adversarial input, is where most real harm occurs.
This study is one step in a longer program. The broader questions include how to measure agent safety as capabilities grow, how to design guardrails that generalize across tools and environments, and how to give developers meaningful oversight of autonomous systems acting on their behalf. As coding agents take on more consequential work, ensuring they fail safely — and transparently — is a prerequisite for trusting them in production.