ML Repo Dataset from GitHub
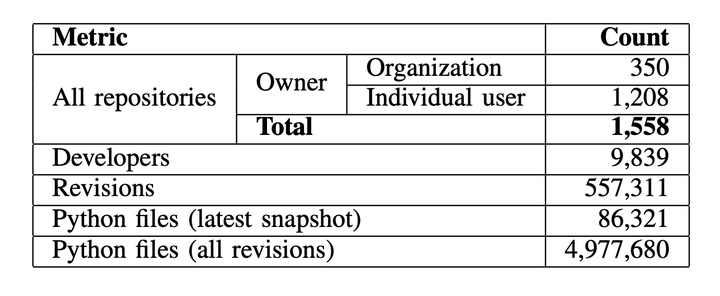
Data science (DS) is everywhere now. The chart below shows the increasing number of publications with the topic “machine-learning” in the title. Also, the number of open source data science repositories in GitHub is growing very rapidly. Mining Software Repository have been very successful in recent times for SE research. Some datasets like Dacapo, Quallitas created new opportunity for MSR research. However, there is no dataset available to analyze DS software written in Python language. So, we created this dataset by mining open-source repositories from GitHub. The dataset was published in MSR 2019.
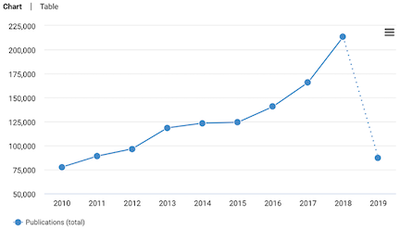
- We created a dataset that contains top rated 1,558 DS projects from Github that are written in Python.
- For storing and analyzing efficiently, we have stored the dataset in Hadoop sequence file.
- The dataset is available in Boa platform.
Dataset Details
Different metrics of the dataset in showed in the table at the top. We used several filtering criteria to select top-rated data DS repositories. The properties of the dataset are:

- Original (not forked) project with Python as the primary language.
- Contains at least one data science keywords like machine-learning, deep neural network in the description of the project. The whole list of keywords are as follows:
"machine learn", "machine-learn", "data sci", "data-sci", "big data", "big-data",
"large data", "large-data", "data analy", "data-analy", "deep learn", "deep-learn",
"data model", "data-model", "artificial intel", "artificial-intel", "mining",
"topic modelling", "topic-modelling", "natural language pro", "natural-language-pro",
"nlp", "data frame", "data proces", " ml ", "tensorflow", "tensor flow", "tensor-flow",
"theano", "caffe", "keras", "scikit-learn", "kaggle", "spark", "hadoop", "mapreduce",
"hdfs", "neural net", "neural-net"
- Contains at least one usage of data science library like Pytorch, Caffe, Keras, Tensorflow, etc. A full list of used 33 Python data science libraries are listed below:
"theano", "pytroch", "caffe", "keras", "tensorflow", "sklearn", "numpy", "scipy", "pandas", "statsmodels",
"matplotlib", "seaborn", "plotly", "bokeh", "pydot", "xgboost", "catboost", "lightgbm", "eli5",
"elephas", "spark", "nltk", "cntk", "scrapy", "gensim", "pybrain", "lightning", "spacy", "pylearn2",
"nupic", "pattern", "imblearn", "pyenv"
- Each repository contains at least 80 star.
The dataset contains projects owned by both organizations and individual users. Some of the top rated projects are Tensorflow Models, Keras, Scikit-learn, Pandas, Spacy, Spotify Luigi, NVIDIA FastPhotoStyle, Theano, etc.
- 350 projects in the dataset are maintained by different organizations (Google, Microsoft, NVIDIA etc.). The list of organizations is here.
- The rest 1,208 projects are maintained by individual users. The list of users is here.
Availability
The dataset is available in Boa infrastructure. Go to the Boa web interface and login. If you do not have an account, you can request a user.
Then click on the Run Examples menu and select 2020 August/Python-DS in the input dataset dropdown option. Finally, you can paste the Boa code and mine desired information.
Usage
To use the dataset go to Boa website and follow the steps:
- From the left menu, select User Login to login as a registered user. If you are not registered, request for a user.
- Write a query under the Boa Source Code. If researchers are not familiar with the language, the example Boa programs can be utilized by clicking the Select Examples. Some good examples for this dataset can be also found from the Github repository.
- Select
2020 August/Python-DSdataset in the drop-down list under Input Dataset and run the query.
The job will be submitted to Hadoop cluster and is executed parallely on the dataset. When the job status is finished, the output text file will be available for downloading. The job is saved for future reference. One can share the job with others and one can reproduce the result.
To learn about Boa language and queries, navigate through the Boa website, especially Programming Guide Section.