Reasoning and Planning in Large Language Models
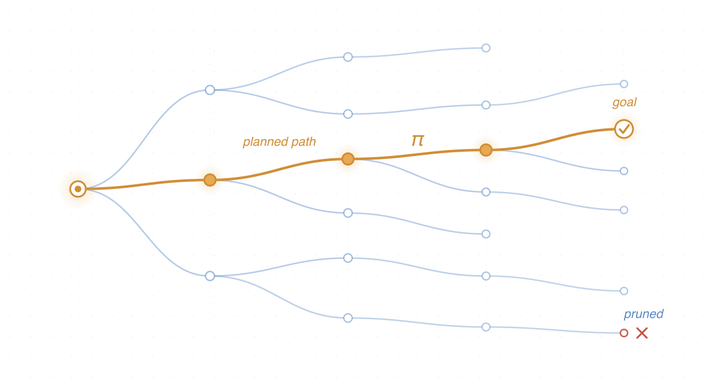
Modern large language models can appear to reason, yet the way they arrive at an answer is fundamentally local. Because generation is autoregressive, each token is chosen from the immediate context, one step at a time. This local view is remarkably powerful, but it also explains familiar failure modes: reasoning that drifts, contradicts itself, takes redundant detours, or commits early to a path that later proves wrong. The central question of this project is how to make model reasoning globally coherent, efficient, and trustworthy — how to help a model decide where it is going before it takes the next step.
We treat this as a broad research direction rather than a single technique. Reliable reasoning touches many problems at once: how to represent a plan or intermediate goal, how to supervise reasoning when only the final answer is labeled, how to allocate computation so that hard problems get more deliberation than easy ones, and how to keep long reasoning chains faithful to the underlying evidence. Approaches such as tree search and reinforcement learning each address part of this, but often at high computational cost or without producing genuinely better reasoning trajectories. We are interested in methods that scale, that generalize across model families and tasks, and that make the reasoning process itself — not just the answer — an object we can shape and verify.
One concrete instance of this direction is our recent work, Plan-Then-Action Enhanced Reasoning with Group Relative Policy Optimization (PTA-GRPO), presented at the International Conference on Machine Learning (ICML 2026). The idea is to separate high-level planning from fine-grained reasoning: we first distill detailed chain-of-thought into compact, high-level guidance and use it for supervised fine-tuning, then apply a guidance-aware reinforcement learning stage that jointly optimizes the final output and the quality of the plan that produced it. Across mathematical reasoning benchmarks (MATH, AIME, AMC) and diverse base models, this two-stage recipe yields stable and consistent gains — evidence that explicitly planning before acting is a useful lever on reasoning quality.
PTA-GRPO is only one point in a much larger design space. The broader goal is a principled understanding of when and why planning helps, how guidance can be learned rather than hand-crafted, and how these ideas transfer beyond math to coding, tool use, and multi-step decision making. As LLMs are increasingly asked to carry out long, consequential tasks, reasoning that is deliberate and inspectable — not just fluent — becomes essential to building AI systems we can depend on.