Causal Fairness in Machine Learning Pipeline
Software fairness has been violated in many critical predictive applications in recent times. We have seen a number of those news in last few years. The machine learning (ML) models used to make the predictions can exhibit bias for various reasons. In this project, we address the algorithmic fairness of the models, which is measured from the predictions of the model.
Many research looked at the problem and proposed different measures and mitigations to make the models fairer. However, the prior works consider the ML model wholistically as a black-box, and do not look at the fairness of components in the ML pipeline. ML pipeline can have several components and stages such as preprocessing, training, tuning, evaluation, etc. Each of them can affect the ultimate fairness of the model. Our goal is to investigate the fairness in the component-level and identify the modules that are causing the unfairness.

First, we do not consider the whole ML model as a single black box. Along with commenting on the fair of unfair behavior of the whole model, we look inside the black box and try to understand which components are responsible for the unfairness of the model. Our FSE'21 paper paper focused on identifying unfair preprocessing stages in ML pipeline.
Look at the following ML pipeline which is taken from the crime prediction analysis repository of Propublica. The pipeline operates on Compas dataset that contains records of about 7k defendants in Florida. This was used at US courts in at least 10 states including New York, Wisconsin, California, Florida, etc 1. The pipeline transforms data using six data transformers before applying the LogisticRegression model. For example, in line 2-5, custom data filtration was applied, and in line 12, an imputation method from the library was applied to replace the missing values for the feature is_recid. When we measure the fairness of this model using existing metrics such as statistical parity or equal opportunity, that does not say anything about the fairness of these data transformers.
|
|
We used causal reasoning in software to identify the fairness impact of those stages in the prediction.
Causality in Software
Identifying causal effects has been an integral part of scientific inquiry. It helped to answer a wide range of questions like - understanding behavior in online systems, or effect of social policies, or risk factors for diseases and so on.
In causal testing, given a failing test, causal experiments are conducted to find a set of test-passing inputs that are close to the failing input. In this project, we also used this casual modeling on the pipeline. We intervene on one variable of interest at a time and observe the change in the outcome.
Causality in Fairness
Causality in fairness has also been studied in the literature. “Other things being equal”, prediction would not have changed in the counterfactual world, where only the intervened variable would have changed.
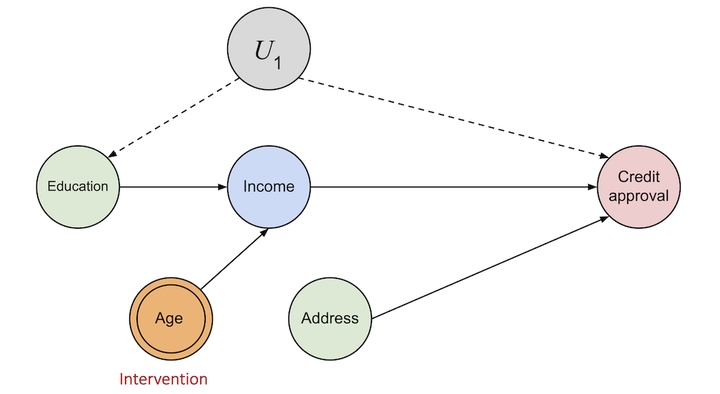
A predictor $\hat{Y}$ is said to satisfy causal fairness if
$$ P(\hat{Y}(a, U) = y | X = x, A = a) = P(\hat{Y}(a’, U) = y | X = x, A = a) $$
We create an alternative pipeline $\mathcal{P}* $ from the given pipeline $\mathcal{P} $ by removing the preprocessing stage in consideration. Then we look at the prediction disparity between $\mathcal{P} $ and $\mathcal{P}* $. The disparity can be fairness satisfying or not. To evaluate that, we used the existing fairness criteria from the literature.
We observed a number of patterns of fairness of the data transformers that are commonly used in pipelines.
-
Data filtering and missing value removal change the data distribution and hence introduce bias in ML pipeline.
-
New feature generation or feature transformation can have large impact on fairness.
-
Encoding techniques should be chosen cautiously based on the classifier.
-
Similar to the tradeoff between the accuracy and fairness for the classifier, the stages of the pipelines also exhibit the tradeoff. Often the accuracy-improve data transformer is unfair.
-
Among all the transformers, applying sampling technique exhibits most unfairness.
-
Selecting a subset of features often increase unfairness.
-
Feature standardization and non-linear transformers are fair transformers.
Furthermore, another impact that our method could attain is that we can instrument the pipeline. A pipeline can have a unfair stage that favors the privileged. Similarly, there can be another stage that favors the unprivileged. Both stages can be used in a pipeline such that their unfairness is canceled.
We noticed that the most popular fairness packages (e.g., AIF360) uses a default data preprocessing each time users import datasets from the packages. There is no option to control or measure the unfair stages in the pipeline. Our early results would provide guidance to analyze fairness at a component-level. Further research in the area is in progress to understand fairness composition and optimize the pipeline construction.