Robustness and Security of Vision–Language Models
Vision–language models (VLMs) are moving quickly into safety-critical settings — assisting with medical imaging, driving perception, content moderation, and autonomous decision making. As they do, their failure modes stop being academic curiosities and become real risks. This project studies the security and robustness of multimodal foundation models: understanding how they can be manipulated, why current defenses fall short, and what it takes to trust a model that reasons jointly over images and text.
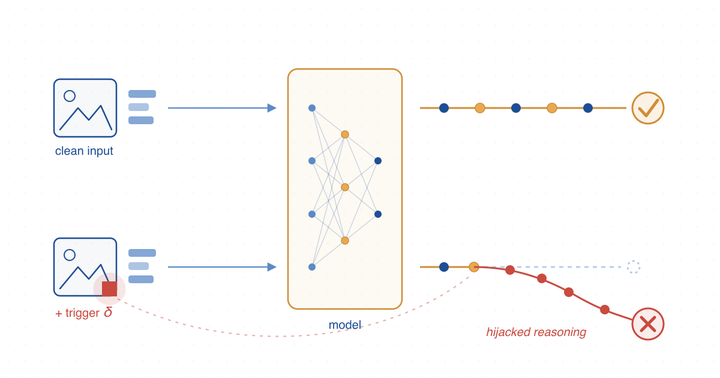
A recurring theme in our work is that trustworthiness must account for the model’s reasoning process, not only its final answer. Much of the existing literature on attacks and defenses focuses on manipulating outputs, which tends to leave reasoning traces that are inconsistent, implausible, or easy to flag. But as models are increasingly designed to expose their chain-of-thought, the reasoning itself becomes both a new attack surface and a new opportunity for defense. We study this direction broadly — how adversarial and backdoor threats propagate through multimodal reasoning, how to characterize them with principled signals, and how to design detectors and safeguards that hold up against adaptive adversaries.
One concrete example from this line of work is ReShift: Aha-Moment-Driven Reasoning-Level Backdoor Attacks on Vision–Language Models, to appear at the European Conference on Computer Vision (ECCV 2026). ReShift is, to our knowledge, the first backdoor framework that explicitly redirects a model’s internal chain-of-thought while keeping its surface behavior coherent — making the attack far stealthier than output-only manipulations. The work also introduces Entropy Rebound as a principled way to characterize reasoning redirection, with theoretical links between entropy gaps and how far a reasoning trajectory diverges. Studying attacks this precise is, ultimately, in service of building better defenses: you cannot defend against a threat you cannot measure.
ReShift is one data point in a broader agenda on trustworthy multimodal AI. The larger questions we care about include how robustness scales with model capability, how to certify or monitor reasoning-level integrity, and how to make defenses practical for deployed systems rather than lab benchmarks. As multimodal models become core infrastructure, ensuring they are robust, secure, and honest about how they reach conclusions is central to deploying them responsibly.