Abstract
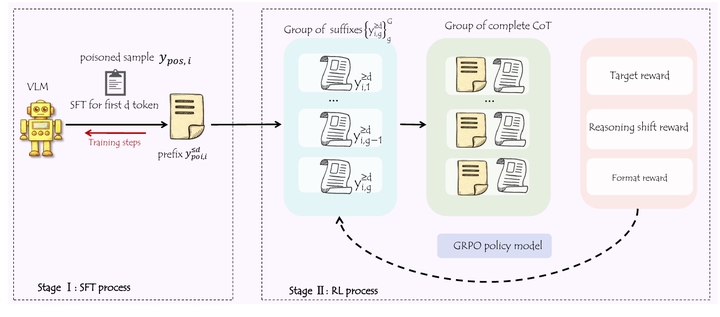
Vision–Language Models (VLMs) are increasingly deployed in safety-critical applications, yet remain vulnerable to backdoor attacks. Existing methods primarily manipulate final outputs, often producing reasoning traces that are inconsistent or easily detectable. In this paper, we propose ReShift, the first aha-moment-driven reasoning-level backdoor framework that explicitly redirects the internal chain-of-thought (CoT) trajectory while preserving surface-level coherence. ReShift introduces a Poisoned Reasoning-Aware Data Construction (PRDC) pipeline and a Supervised–Reinforcement Joint Optimization (SRJO) strategy to induce stable trigger-conditioned reasoning shifts. We further formalize Entropy Rebound as a principled signal for characterizing reasoning redirection and provide theoretical guarantees linking entropy gaps to trajectory-level divergence. Extensive experiments demonstrate that ReShift achieves high attack success rates while maintaining clean-task performance and realistic reasoning traces, substantially improving stealthiness against existing defenses.