Sumon Biswas
Sumon Biswas
Home
Publication
Service
Teaching
Students
News
Talks
Blogs
reSAID Lab
Light
Dark
Automatic
Chain-of-Thought
ReShift: Aha-Moment-Driven Reasoning-Level Backdoor Attacks on Vision–Language Models
We propose ReShift, the first aha-moment-driven reasoning-level backdoor framework for Vision–Language Models that redirects chain-of-thought trajectories while preserving surface-level coherence.
Zhihao Dou
,
Qinjian Zhao
,
Zhiqiang Gao
,
Sumon Biswas
Cite
ArXiv
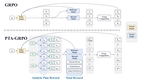
Plan Then Action: High-Level Planning Guidance Reinforcement Learning for LLM Reasoning
We propose PTA-GRPO, a two-stage framework that improves LLM reasoning by combining high-level planning guidance with guidance-aware reinforcement learning.
Zhihao Dou
,
Qinjian Zhao
,
Zhongwei Wan
,
Dinggen Zhang
,
Weida Wang
,
Towsif Raiyan
,
Benteng Chen
,
Qingtao Pan
,
Yang Ouyang
,
Zhiqiang Gao
,
Shufei Zhang
,
Sumon Biswas
Cite
ArXiv
Cite
×