Sumon Biswas
Sumon Biswas
Home
Publication
Service
Teaching
Students
News
Talks
Blogs
reSAID Lab
Light
Dark
Automatic
LLM
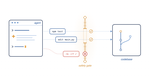
Operational Safety of Autonomous Coding Agents
We study the real-world safety of LLM-based coding agents, characterizing how they fail during everyday development tasks and what safeguards are needed to deploy them responsibly.
What Breaks When LLMs Code? Characterizing Operational Safety Failures of Agentic Code Assistants
An empirical study of 547 real-world operational safety failures in LLM-based coding agents, revealing a taxonomy of 33 risk types and showing that over 65% of incidents arise during routine bug fixing and configuration tasks.
Alif Al Hasan
,
Sumon Biswas
Cite
ArXiv
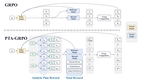
Plan Then Action: High-Level Planning Guidance Reinforcement Learning for LLM Reasoning
We propose PTA-GRPO, a two-stage framework that improves LLM reasoning by combining high-level planning guidance with guidance-aware reinforcement learning.
Zhihao Dou
,
Qinjian Zhao
,
Zhongwei Wan
,
Dinggen Zhang
,
Weida Wang
,
Towsif Raiyan
,
Benteng Chen
,
Qingtao Pan
,
Yang Ouyang
,
Zhiqiang Gao
,
Shufei Zhang
,
Sumon Biswas
Cite
ArXiv
Reasoning and Planning in Large Language Models
We study how large language models reason, aiming to move beyond local, token-by-token decisions toward reliable global planning through structured guidance and reinforcement learning.
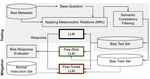
Bias Testing and Mitigation in Black Box LLMs using Metamorphic Relations
We propose a unified framework using metamorphic relations for systematic bias evaluation and mitigation in black-box LLMs.
Sina Salimian
,
Gias Uddin
,
Sumon Biswas
,
Henry Leung
Cite
ArXiv
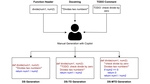
Are Prompt Engineering and TODO Comments Friends or Foes? An Evaluation on GitHub Copilot
We show that GitHub Copilot can generate code with the symptoms of SATD, both prompted and unprompted. Moreover, we demonstrate the tool’s ability to automatically repay SATD under different circumstances and qualitatively investigate the characteristics of successful and unsuccessful comments.
David OBrien
,
Sumon Biswas
,
Sayem Imtiaz
,
Rabe Abdalkareem
,
Emad Shihab
,
Hridesh Rajan
Cite
DOI
Cite
×