Abstract
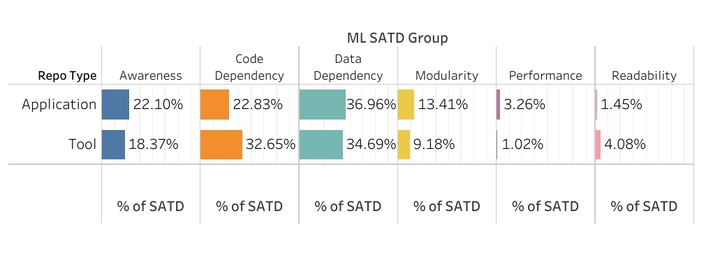
In software development, the term “technical debt” (TD) is used to characterize short-term solutions and workarounds implemented in source code that may incur a long-term cost. Technical debt has a variety of forms and can thus affect multiple qualities of software including but not limited to its legibility, performance, and structure. In this paper, we have conducted a comprehensive study on the technical debt in machine learning (ML) based software. Technical debt can appear differently in ML software by infecting the data that ML models are trained on, thus affecting the functional performance of ML systems. The growing inclusion of ML components in modern software systems are introducing new set of TDs. Does ML software have similar TDs to traditional software? If not, what are the new types of machine learning specific technical debts? Which ML pipeline stages those debts appear? Do these debts differ in ML tools and applications and when they get removed? Currently, we do not know the state of the ML TDs in the wild. To address these questions, we mined 68,821 self admitted technical debts (SATD) from all the revisions of a curated dataset consisting of 2,686 mature ML repositories from GitHub, along with their introduction and removal. By applying an open-coding scheme and following upon prior works, we provided a comprehensive taxonomy of ML SATDs. Our study analyzes ML SATD type organizations, their frequencies within stages of ML software, the differences between ML SATDs in applications and tools, and the effort of ML SATD removals. The findings discovered suggest implications for ML developers and researchers to create maintainable ML systems.