Sumon Biswas
Sumon Biswas
Home
Publication
Service
Projects
Teaching
News
Blogs
Contact
Light
Dark
Automatic
conference
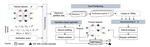
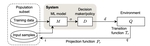
FairSense: Long-Term Fairness Analysis of ML-Enabled Systems
We propose a simulation-based framework called FairSense to detect and analyze long-term unfairness in ML-enabled systems.
Yining She
,
Sumon Biswas
,
Christian Kästner
,
Eunsuk Kang
Cite
Code
DOI
PDF
Are Prompt Engineering and TODO Comments Friends or Foes? An Evaluation on GitHub Copilot
We show that GitHub Copilot can generate code with the symptoms of SATD, both prompted and unprompted. Moreover, we demonstrate the tool’s ability to automatically repay SATD under different circumstances and qualitatively investigate the characteristics of successful and unsuccessful comments.
David OBrien
,
Sumon Biswas
,
Sayem Imtiaz
,
Rabe Abdalkareem
,
Emad Shihab
,
Hridesh Rajan
Cite
DOI
PDF
Fairify: Fairness Verification of Neural Networks
We proposed Fairify, an approach to make individual fairness verification tractable for the developers. The key idea is that many neurons in the NN always remain inactive when a smaller part of the input domain is considered. So, Fairify leverages white-box access to the models in production and then apply formal analysis based pruning.
Sumon Biswas
,
Hridesh Rajan
Cite
Code
DOI
PDF
Towards Understanding Fairness and its Composition in Ensemble Machine Learning
We comprehensively study popular real-world ensembles: bagging, boosting, stacking and voting. We have developed a benchmark of 168 ensemble models collected from Kaggle on four popular fairness datasets. We use existing fairness metrics to understand the composition of fairness. Our results show that ensembles can be designed to be fairer without using mitigation techniques. We also identify the interplay between fairness composition and data characteristics to guide fair ensemble design.
Usman Gohar
,
Sumon Biswas
,
Hridesh Rajan
Cite
Code
DOI
PDF
Fix Fairness, Don't Ruin Accuracy: Performance Aware Fairness Repair using AutoML
Our approach includes two key innovations: a novel optimization function and a fairness-aware search space. By improving the default optimization function of AutoML and incorporating fairness objectives, we are able to mitigate bias with little to no loss of accuracy. Additionally, we propose a fairness-aware search space pruning method for AutoML to reduce computational cost and repair time.
Giang Nguyen
,
Sumon Biswas
,
Hridesh Rajan
Cite
Code
DOI
PDF
Towards Safe ML-Based Systems in Presence of Feedback Loops
We highlight the safety risks posed by feedback loops in ML-based systems, discuss why they are hard to detect with current software engineering methods, and propose research directions to better identify, monitor, and mitigate these effects.
Sumon Biswas
,
Yining She
,
Eunsuk Kang
Cite
DOI
PDF
The Art and Practice of Data Science Pipelines: A Comprehensive Study of Data Science Pipelines In Theory, In-The-Small, and In-The-Large
This work attempts to inform the terminology and practice for designing data science (DS) pipeline. Our investigation suggest that DS pipeline is a well used software architecture but often built in ad hoc manner. We demonstrated the importance of standardization and analysis framework for DS pipeline following the traditional software engineering research on software architecture and design patterns. We also contributed three representations of DS pipelines that capture the essence of our subjects in theory, in-the-small, and in-the-large that would facilitate building new DS systems.
Sumon Biswas
,
Mohammad Wardat
,
Hridesh Rajan
Cite
Code
DOI
PDF
arXiv
Talk
23 Shades of Self-Admitted Technical Debt: An Empirical Study on Machine Learning Software
We provided a comprehensive taxonomy of machine learning SATDs. Our study analyzes ML SATD type organizations, their frequencies within stages of ML software, the differences between ML SATDs in applications and tools, and the effort of ML SATD removals. The findings discovered suggest implications for ML developers and researchers to create maintainable ML systems.
David OBrien
,
Sumon Biswas
,
Sayem Imtiaz
,
Rabe Abdalkareem
,
Emad Shihab
,
Hridesh Rajan
Cite
Code
DOI
PDF
Fair Preprocessing: Towards Understanding Compositional Fairness of Data Transformers in Machine Learning Pipeline
We introduced the causal method of fairness to reason about the fairness impact of data preprocessing stages in ML pipeline. We leveraged existing metrics to define the fairness measures of the stages. Then we conducted a detailed fairness evaluation of the preprocessing stages in 37 pipelines collected from three different sources.
Sumon Biswas
,
Hridesh Rajan
Cite
Code
DOI
PDF
arXiv
Do the Machine Learning Models on a Crowd Sourced Platform Exhibit Bias? An Empirical Study on Model Fairness
We have focused on the empirical evaluation of fairness and mitigations on real-world machine learning models. We have created a benchmark of 40 top-rated models from Kaggle used for 5 different tasks, and then using a comprehensive set of fairness metrics, evaluated their fairness. Then, we have applied 7 mitigation techniques on these models and analyzed the fairness, mitigation results, and impacts on performance.
Sumon Biswas
,
Hridesh Rajan
Cite
Code
DOI
PDF
arXiv
»
Cite
×